This was made abundantly clear when M. and I looked for a place to eat in our neighborhood last night. It seemed that just about every restaurant within 5 miles was regarded as excellent -- the average score was over 9.0. Oddly, this included more than a few that we had tried before and wouldn't recommend to anyone. Some of places that received high scores probably wouldn't even pass a health inspection, let alone merit a "9.0". Yet every last one of them was "Best Of Citysearch," no matter how awful they really were. Yes, this even includes an ordinary McDonald's, which was not only a "Best Of," but also had an overall rating of 8.5 and was "Recommended."

Obviously there is some tremendous rating inflation going on at Citysearch. Which just makes it all the more amusing when you see a "Best Of Citysearch" award on a restaurant door, though I do remember when that might have meant something.
Yet the relative ratings were actually rather reasonable. A restaurant that receives a 9.5 is often better than one that receives a 7.5. But scanning through the list was an exercise in frustration -- it is tremendously difficult to tell what places are even worth looking at in detail.
I found myself adjusting the scores in my head -- normalizing the low end of the ratings out of the picture, and focusing more on the 8's and 9's. And I wondered, what if one could edit the Citysearch site itself to adjust the scores automatically. Fortunately, that's precisely what the Firefox Greasemonkey extension is designed to enable. Greasemonkey lets the end-user customize their browser to make personalized modifications to other people's websites on a case-by-case basis. So all I needed to do was write a simple bit of JavaScript to dynamically rewrite the Citysearch pages and adjust the scores to a more reasonable set of values.
Writing the actual code was pretty simple. (Simple enough, in fact, to be done while watching the Patriots lose and the Red Sox win.) As is usually the case with JavaScript, the hardest part is figuring out script APIs without any canonical source of documentation. But once you bite that bullet, writing Greasemonkey scripts is pretty painless.
So after an hour or two of work, version 0.1 of the script was finished. Here is a before and after view of a Citysearch page (click for larger view) with and without the Normalize Citysearch Greasemonkey script enabled:
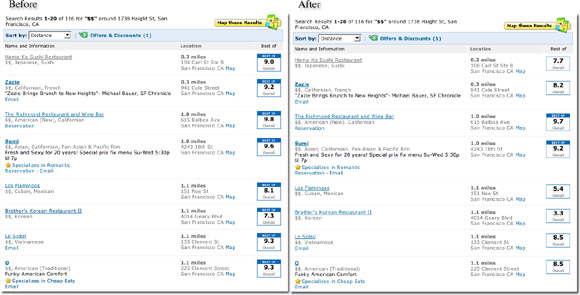
If you are interested, you can install the Normalize Citysearch script yourself in just a matter of minutes. Simply follow these directions:
- Install Firefox
- Install Greasemonkey
- Restart Firefox
- Load the Normalize Citysearch script
- Click on Tools/Install This User Script
- Search citysearch.com
One thing that could be done to improve this script would be to crawl the Citysearch site and capture all of the ratings. This would allow for an algorithm that could equalize the histogram of a localized subset of ratings. Even easier would be to approxmiate this by logarithmically normalizing according to some fixed constant, though an accurate model of the current distribution would still be necessary to make a good guess at the constant. (Please take a stab at this if you are mathematically inclined!) The source is available under a Creative Commons license and can be found in the unto.net SVN repository. Please add your comments here or send me a patch if you have any ideas on how to improve the Normalize Citysearch greasemonkey script.
Update 2005-10-05:
Thinking a bit more about how to better adjust the ratings, there are apparently a number of approaches. The problem is clear -- if you could plot a histogram of all of the Citysearch rankings then the bias towards 8's and 9's would be obvious. The histogram would be shaped roughly like a bell, but the top of the bell would be leaning far, far to the right. (The mean has to be around 8 or so.)
Interestingly, this process is analogous to generating the histogram of the pixel values in a greyscale image. In fact, some of the same algorithms that help with image enhancement could be used here as well. The easiest of these enhancement algorithms is a simple linear stretch of all of the values, shifting the non-existent rankings (0 through 4.5 or so) off entirely, and scaling the remaining values linearly. This is what the first version of the Normalize Citysearch greasemonkey script did.
Unfortunately the simple linear stetch didn't quite give the results I hoped for. Fortunately, the documentation for a program called tclSadie had a nice overview of image adjustment algorithms. Nothing too sophisticated, but the page did write many of the algorithms out all in one place with useful descriptions. I suspect that the overall best results would be found by using a reference "image" to generate a least-squares lookup table and adjust accordingly toward that. With that approach you could normalize toward a smooth bell curve, or even a completely flat distribution, without much effort. (I.e., the reference "image" can be generated on-the-fly with a simple function.)
But instead of implementing the reference table algorithm, I changed the linear scaling to a partitioned linear scaling (the above site called it "piecemeal" linear stretch) and defined a few broad rating ranges and adjusted them each independently. Please keep in mind that I'm not a mathemetician and I don't really know what I'm talking about here. (But I may try the logarithmic scaling just to see how it works.)
All of this said, Citysearch could consider renormalizing their own data on a nightly basis. They could easily examine the real histogram and identify any overwhelming bias. They could then use any one of these algorithms to reshape that curve to give more useful information to their users. They could even try to address some of Sean'scomments regarding the underlying user experience concerns.
Okay, enough of this, time to move on...