First, and perhaps the most fun because it includes video, Tantek Ìàelikposted a videoblog about his experience using the OpenSearch format to plug the Technorati search engine into IE7.

Tantek also raises some interesting questions/concerns about the Google Toolbar and how it interacts with the browser's search box. Tantek speculates that the toolbar is trying to prevent the user from switching their search engine. Though I haven't asked the team about it directly, my impression is that the toolbar is not trying to stop the user from making a choice, but rather it is helping to prevent both malicious code (i.e., viruses) and browser upgrades from switching the search box without the user's permission. Sadly, this protection was necessary in the past, though perhaps less so with all of the improvements made in IE7.

The Encyclopedia Britannica launched open.britannica.com, a bold move in the changing environment of open content. As someone who grew up with a set of EB encyclopedias on the shelf, I have a warm nostalgic association with the brand, and I sincerely hope that they succeed in embracing the network and find the right balance between editorial quality, user generated contributions, and open content syndication. With open.britannica.com they are demonstrating their willingness and eagerness to explore the new models, and more power to them.
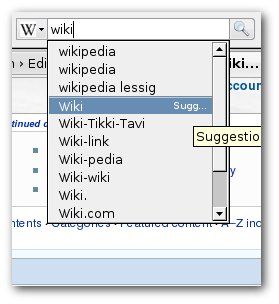
Meanwhile, MediaWiki, the software that powers Wikipedia, isn't standing still. I recently noticed that they rewrote their plugin API and are now shipping with OpenSearch support built-in.
Even better, they support the Firefox-style OpenSearch suggestions extension. To try it out, go to Wikipedia using Firefox, find the search box in the upper right corner of your browser, click on the drop-down (if you haven't changed it, it will be showing the Google "G" logo), and select "Wikipedia (English)". Now start typing a search query; it should auto-complete phrases based on live data from the Wikipedia servers. Cool, no?


Creative Commons licensed photograph by Christopher Schmidt.
And thanks to Andrew Turner, we're making progress on a GeoRSS-based layer, the first rough draft of which can be found on the OpenSearch wiki. This is very much a community-driven process, with a focus on meeting the needs of the 80% case first.

I don't have an appropriate picture for this next one, but everyone loves lolcats, so there you have it.
Microsoft, one of the strongest supporters of and contributors to OpenSearch, proposed using ‰ÛÏrel‰Û? to identify the relationship of a <url /> to its source. Great idea, and it is something we can make it back compatible, so it will make an appearance in OpenSearch 1.1 Draft 4.

...
And that's all I have. Please leave a comment if you know of or are working on something exciting related to OpenSearch.